
本文章所有内容仅供学习和研究使用,不提供具体模型和源码。若有侵权,请联系我立即删除
某盾空间推理点选训练
开始
整体思路
目标检测:识别图片中小图的坐标
切割图片:根据坐标切割小图
分类训练:识别每个小图的方向颜色朝向
1、样本准备
批量存储对应图片(200-300)
图片存于
image文件中,提示文本换行存在text.txt
图片爬去过程省略,主要记录点选训练思路,不涉及逆向。也可以用自动化获取样本
2、分词分类
对抓去的txt.txt 进行语义分析统计
tools.py 分词,统计词频,删除无用词
def split_jieba():
# 1. 读取分词
prompt_path = "text.txt"
prompt_list = []
with open(prompt_path, 'r', encoding = 'utf-8') as f:
for line in f.readlines():
print(line.strip().replace('请点击', ''))
prompt_list.append(line.strip().replace('请点击', ''))
# 2.分词,统计词频
word_dict = {}
for line in prompt_list:
words = jieba.cut(line) # 分词
for word in words:
if word in word_dict.keys():
word_dict[word] += 1
else:
word_dict[word] = 1
print(word_dict)
# 删除掉无用词
delete_list = ["的", "大写", "小写", "一样", "朝向", "数字", "颜色"]
for word in delete_list:
del word_dict[word]
# 排序
word_dict = sorted(word_dict.items(), key = lambda x:x[0], reverse = False)
print(word_dict)
2、分析分类
# 大写字母
upper = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
# 小写字母
lower = "abcdefghijklmnopqrstuvwxyz"
# 数字
number = "0123456789"
# 三维物体
three = ["圆柱", "圆锥", "球", "立方体"]
# 颜色
color = ["红色", "绿色", "黄色", "蓝色", "灰色"]
# 朝向
orientation = ["侧向", "正向"]经过分类,观察一共3个维度。
大小写数字物体(下文统称【名称分类】) 4种为一个分类,颜色为一个分类,朝向为一个
很多类似的字母无法区分,全部视为大写,后期逻辑统一处理,比如:V v Ww Xx等...
当我们增加分类时,就意味着我们需要增加打标签的样本!借鉴吾爱大佬[1] 的一个思路,我们可以将图片的颜色剥离,然后根据名称分类和朝向来进行132种分类。颜色部分则单独训练。这样做的好处是显而易见的,分类的数量减少,意味着我们打标签的成本大大降低。但本文在这个思路基础上将三个维度分别进行训练,具体思路如下:
tools.py 分类代码 生成classes.txt
def combine_prompt():
# 大写字母
upper = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
# 小写字母
lower = "abcdefghijklmnopqrstuvwxyz"
# 数字
number = "0123456789"
# 三维物体
three = ["圆柱", "圆锥", "球", "立方体"]
# 颜色
color = ["红色", "绿色", "黄色", "蓝色", "灰色"]
# 朝向
orientation = ["侧向", "正向"]
# 生成所有结果组合
result = []
# upper、lower、number、three为同类型,只能选一个,格式 [upper, lower, number, three]_color_orientation
for a in [upper, lower, number, three]:
for b in a:
for d in orientation:
# for c in color:
# result.append(f'{b}_{c}_{d}')
result.append(f'{b}_{d}')
print(len(result))
print(result)
# 写入文件
with open("./classes.txt", "w", encoding="utf-8") as f:
for line in result:
f.write(line + "\n")
3、训练思路
标注大约100到200张图片,训练一个正向和侧向的模型。
标注大约100到200张图片,训练一个颜色模型。
利用上述模型定位并切割出小图,训练一个分类模型。
这样每张图片经过这三个模型处理后就能得到结果。同时,我们也可以再拿一批新的图片经过这三个模型,并自动生成方向、颜色、分类的样本,然后再训练一个综合模型。这样一来,我们就可以更有效地处理和分类大量的图片数据。
我标记了200张 标记两个维度 名称分类_朝向 有不同思路的欢迎留言交流
4、打标训练样本
详细情看另外一篇文章 labelimg标注工具,不过多解释。
使用 labelimg 进行打标
pip install labelimg
# images 达标图片目录 classes.txt 类别
labelimg ./images ./classes.txt5、切割图片
import cv2
from PIL import ImageFont
class Crop(object):
def __init__(self, bigImgPath: str, save_paths: str):
self.save_paths = save_paths
self.image = cv2.imread(bigImgPath)
def crop_image_from_coordinates(self, coordinatesList: list):
# coordinatesList 打标后面的那个左边
result = []
for ind, coordinates in enumerate(coordinatesList):
data = {}
x1, y1, x2, y2 = coordinates[:4]
x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2)
cropped_image = self.image[y1:y2, x1:x2] # 裁切的小图
save_paths = fr"{self.save_paths}\{ind}.jpg"
print(save_paths)
cv2.imwrite(save_paths, cropped_image)
data['xyxy'] = x1, y1, x2, y2
data['savePath'] = save_paths
result.append(data)
return result6、分类训练(YOLO v8)
train.py 对切割的颜色,名称分类,朝向进行训练
from ultralytics import YOLO
model = YOLO('yolov8n-cls.pt', task='classify') # 分类训练
results = model.train(data='[切割图片路径]', epochs=50, imgsz=320, workers=0, cache=True, device='0')
三个维度训练结果



val.py 验证代码
from ultralytics import YOLO
model = YOLO('[训练的模型]', task='classify')
results = model.predict(source=r'[预测路径,或图片]', show=True, save=True, imgsz=320, device='0')
for result in results:
cls_dict = result[0].names
cls_id = result.probs.top1
cls_result = cls_dict[cls_id]
print(f"当前图片的结果是:{'侧' if cls_result == 'ce' else '正'}")7、目标检测
我们可以利用前面3个模型的任意一个模型做目标检测
train2.py 目标检测
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
from ultralytics import YOLO
model = YOLO('yolov8n.pt', task='detect')
if __name__ == '__main__':
# [train, val, predict, export, track, benchmark] 训练、验证、预测、模型转换、追踪、基准模型评估
model.train(data=fr'./slider.yml', epochs=100, cache=True, imgsz=320, batch=16, workers=0, device='0')
"""
data 数据集来源配置
epochs 训练论数v
cache
imgsz ai训练图片的size,大图片建议640 小320 越大越吃性能
task 【detect、segment、classify、pose】 四种任务类型 检测、分割、分类、姿态
"""slider.yml 文件 配置文件
path: D:\yfl_50\box_200
train: ./images/train
val: ./images/val
test: # TEST IMAGES (OPTIONAL)
nc: 1
names: ["box"]
val2.py 进行模型检测,返回坐标值
from ultralytics import YOLO
model = YOLO(r"best_mu.pt", task="detect") # build a new model from scratch
results = model.predict(source=r"D:\yfl_50\img\00abb37393c443fec2865ddfef64fbf2.jpg", show=False,save=False)
# 输出坐标信息
print(f"标签名字:{results[0].names}, \n目标类:{ results[0].boxes.cls.tolist()}")
print(results)
cls_dict = results[0].names
cls_all = results[0].boxes.cls.tolist()
xyxy_all = results[0].boxes.xyxy.tolist()
for i in range(len(cls_all)):
label_name = cls_dict[int(cls_all[i])]
box_xyxy = xyxy_all[i]
box_mid_xy = [(box_xyxy[0] + box_xyxy[2])/2, (box_xyxy[1] + box_xyxy[3])/2]
print(F"目标点{i} :标签名字:{label_name}, 中心坐标:{box_mid_xy}, xyxy坐标: {box_xyxy}")
目标检测结果


8、三个模型合并
过程很简单就是一些逻辑,不在啰嗦了....
下面是一下结果识别图
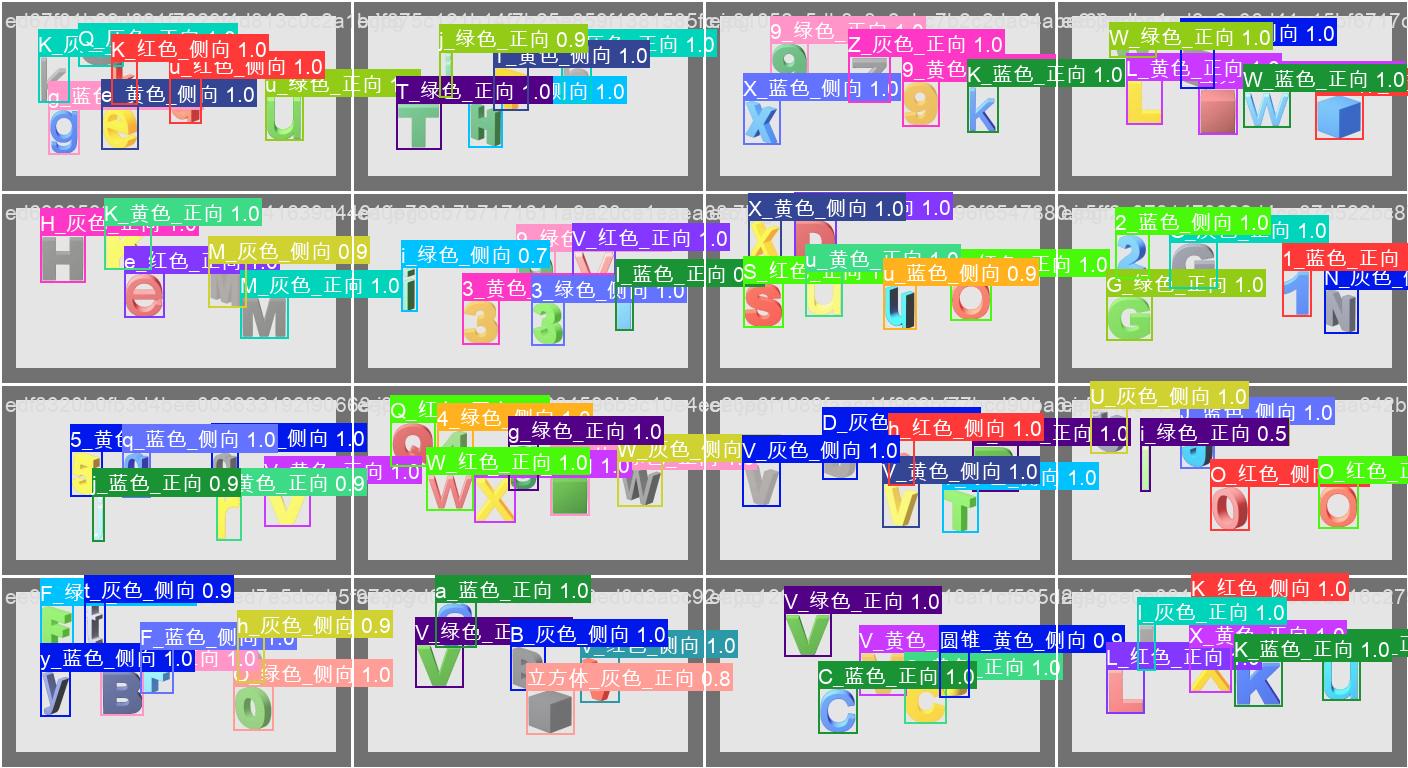
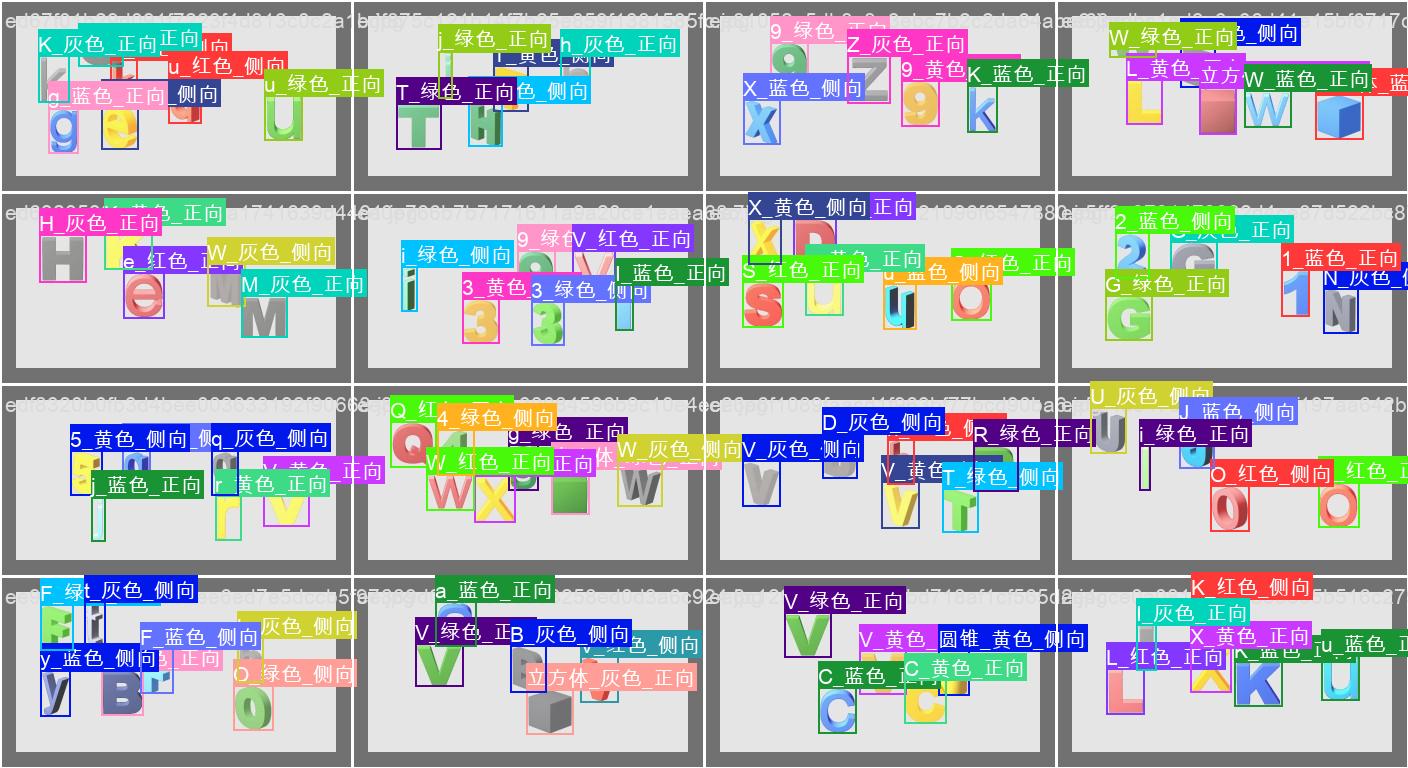
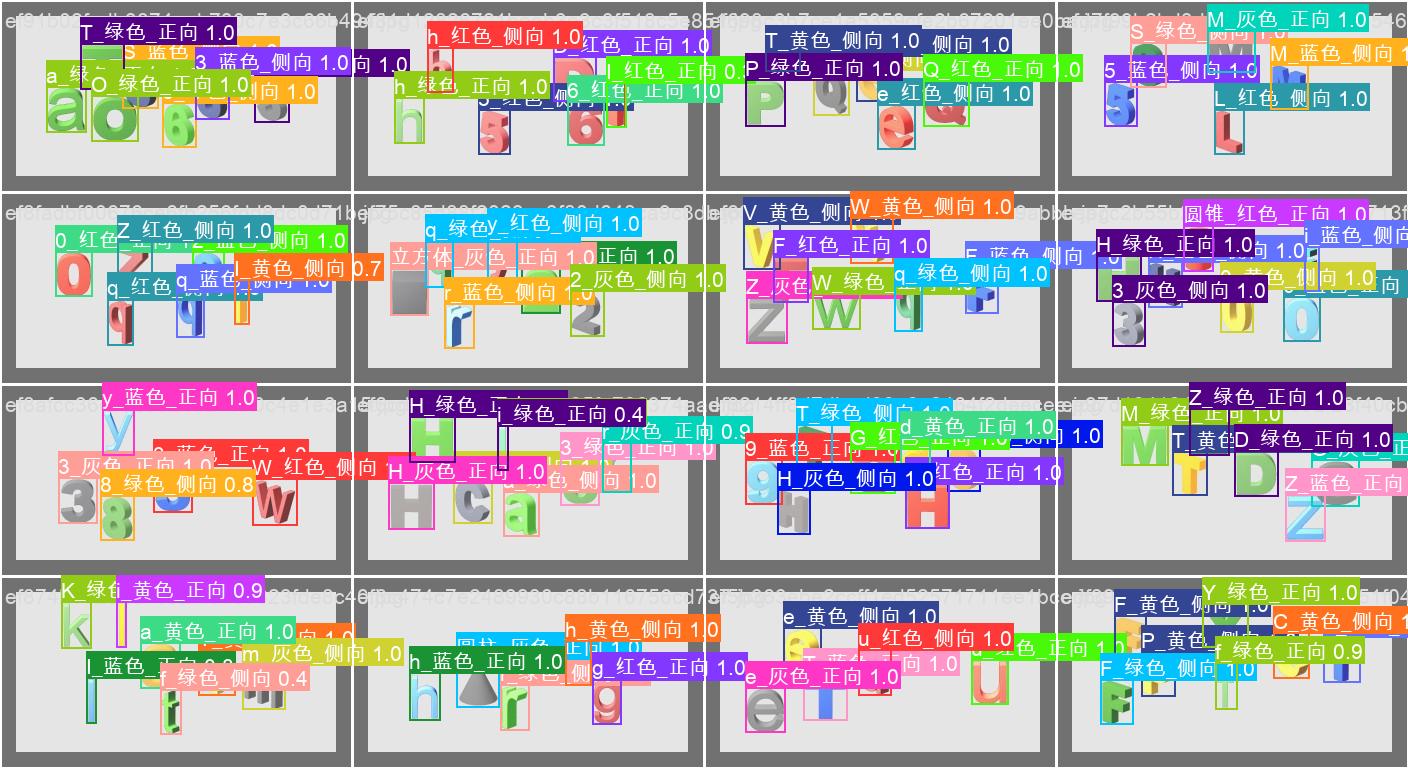

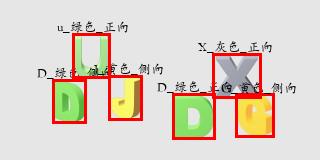
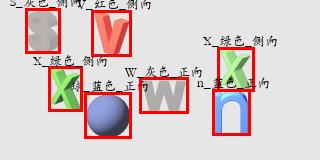
9、语义逻辑分析
暂时还没有写,尽快更新
10、其他
提过一些我用到的代码
tools.py 自动分类
def train_val_mkdir(fileDir):
"""
自动分类 创建 train val文件,按比例分类
:param fileDir: 数据集的Path
:return: None
"""
TRAIN = 8
count = len(os.listdir(fileDir))
count = count // 2
train_count = int(count * (TRAIN * 0.1))
val_count = count - train_count
print(f'当前图片总数为:{train_count}张 | 比例{TRAIN}:{10 - TRAIN} | train【{train_count}】张 val【{val_count}】张')
cou = 0
for file in os.listdir(fileDir):
if file == "classes.txt":
continue
if file.split('.')[-1] != 'txt':
continue
if cou < train_count:
fileName = 'train'
else:
fileName = 'val'
print(f'总体比例是train:val{TRAIN}:{10 - TRAIN}|正在处理第{cou}个文件|当前分类为:{fileName}| {file}')
images_path = fr'{fileDir}/images/{fileName}'
if not os.path.exists(images_path):
os.makedirs(images_path)
labels_path = fr'{fileDir}\labels\{fileName}'
if not os.path.exists(labels_path):
os.makedirs(labels_path)
name = file.split('.')[0]
txtPath = fr'{fileDir}\{name}.txt'
imgPath = fr'{fileDir}\{name}.jpg'
shutil.move(txtPath, labels_path)
shutil.move(imgPath, images_path)
cou += 1小图合并
def add_image_to_background(resultList):
# 创建一个白色的320x160图片
background = np.ones((160, 320, 3), dtype=np.uint8) * 255
# 加载中文字体文件
font_path = r'D:\yfl_50\simsunb.ttf'
# 字体的格式
fontStyle = ImageFont.truetype(font_path, 15, encoding="utf-8")
for coordinates in resultList:
print(coordinates)
# 读取小图
small_image = cv2.imread(coordinates['savePath'])
# 获取坐标
x1, y1, x2, y2 = coordinates['xyxy']
# 将小图放置在大图上
background[y1:y2, x1:x2] = small_image
# 在大图上绘制红色框和标注信息
result = coordinates['result']
cv2.rectangle(background, (x1, y1), (x2, y2), (255, 0, 255), 2)
cv2.putText(background, result, (x1, y1 - 10), cv2.FONT_HERSHEY_COMPLEX , 0.5, (0, 0, 255), 1)
# print(result)
# background = cv2AddChineseText(background, result, (x1, y1 - 10), (0, 0, 255), 1)
# print(background)
# 保存大图
cv2.imwrite(r'result.jpg', background)
坐标转换
# 将四个相对位置的坐标转换为 LabelImg 标注工具输出的格
def convert_to_center_width_height(x1, y1, x2, y2, width=320, height=160):
# 计算中心坐标
center_x = (x1 + x2) / 2
center_y = (y1 + y2) / 2
# 计算宽度和高度
box_width = x2 - x1
box_height = y2 - y1
# 归一化处理
norm_center_x = center_x / width
norm_center_y = center_y / height
norm_box_width = box_width / width
norm_box_height = box_height / height
return norm_center_x, norm_center_y, norm_box_width, norm_box_height绘制边框
from PIL import Image, ImageDraw, ImageFont
# 打开图片
img = Image.open(fname)
draw = ImageDraw.Draw(img)
for i in range(len(cls_all)):
label_name = cls_dict[int(cls_all[i])]
box_xyxy = xyxy_all[i]
box_mid_xy = [(box_xyxy[0] + box_xyxy[2])/2, (box_xyxy[1] + box_xyxy[3])/2]
print(F"目标点{i} :标签名字:{label_name}, 中心坐标:{box_mid_xy}, xyxy坐标: {box_xyxy}")
coordinates = [float(i) for i in box_xyxy]
# 提取坐标信息
x1, y1, x2, y2 = coordinates
# 绘制边框
draw.rectangle([x1, y1, x2, y2], outline='red', width=3)
# 设置字体和字体大小
font = ImageFont.truetype("STKAITI.TTF", 13)
# 计算文本位置
text_width, text_height = draw.textsize(label_name, font)
# text_x = x1 + (x2 - x1 - text_width) // 2
# text_y = y1 + (y2 - y1 - text_height) // 2
# 绘制文本和背景
# draw.rectangle([x1 - 17, y1 - 15, x1 + text_width - 12, y1 + text_height - 12], fill='black')
draw.text((x1 - 15, y1 - 15), label_name, fill='black', font=font)参考文章和鸣谢
[1]: 参考文章 [吾爱破解] [验证码识别]易盾空间推理验证码识别详细流程 作者:s1lencee
[2]: 参考文章 [知识星球](付费内容不便公开) 作者: 时一姐
特别感谢强哥和时一姐,以及我的兄弟飞龙为我提供了帮助,感谢!以此记录!
———— END ————